
Googleの新しいディープラーニング(深層学習)マシン「PlaNet」は、画像から街頭の風景や屋内の物体の撮影場所を特定する作業において、人間を上回る能力を発揮する。
Googleはあらゆる写真を分析して、その撮影場所を正確に特定する能力を得たことになる。PlaNetの開発チームによると、同マシンは「人間を超える精度」でそれを行うことができるという。
Googleのニューラルネットワーク分野での取り組みであるPlaNetは、画像のピクセルだけを使ってこの作業ができると、MIT Technology Reviewは報じた。
このプロジェクトを主導するのは、Googleのコンピュータビジョン専門家であるTobias Weyand氏だ。Weyand氏の最新の論文によると、研究チームは「Google+」から取得した、ジオタグ(Exifの位置情報)データや画像メタデータを含む大量の画像データセットを使って、畳み込みニューラルネットワークに学習させたという。
Weyand氏が論文で述べているように、過去の取り組みは画像検索の問題として位置情報にアプローチしており、ランドマークを抽出して、大まかな位置を提示することしかできなかった。
PlaNetはこの作業を分類の問題として扱っており、天候パターンや植生、路面標識、建築物の細部など、複数の視覚的手がかりを使って、正確な位置を特定することもある。
このアプローチの採用により、PlaNetは「写真について確信のなさを表現」することができる。例えば、エッフェル塔の画像の撮影場所についてはかなりの自信を示すが、フィヨルドの画像に関しては、ニュージーランドとノルウェーの両方の可能性を提示する。
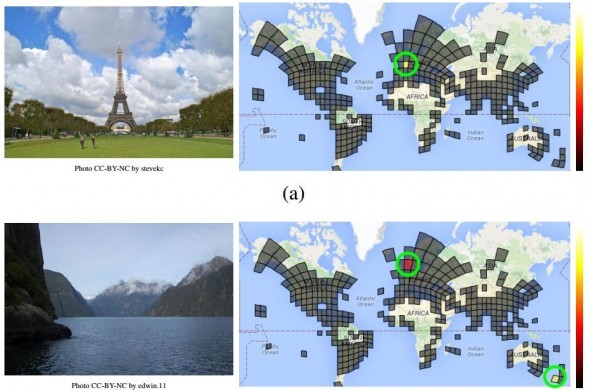
このシステムは、世界を2万6000個の正方形からなる碁盤目に分割することで開発された。一定の場所で撮影された画像が多ければ多いほど、その場所の正方形が拡大するので、都市は過疎地より大きい。一方、海は完全に無視されている。
ネットワークに学習させるため、Googleはウェブから取得した、Exif画像メタデータを含む1億2600万点の画像のデータセットを採用し、9100万点を学習用に、3400万点を検証用に分類した。
その後、PlaNetの能力を10人の「旅行経験豊富な人間」と比較するため、研究チームはウェブサイト「Geoguessr」と「Street View」の画像集を使用した。論文によると、PlaNetは50ラウンドのうち、28ラウンドで勝利を収めたという。
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 データ統合のススメ
データ統合のススメ
OMO戦略や小売DXの実現へ
顧客満足度を高めるデータ活用5つの打ち手
 脱炭素のために”家”ができること
脱炭素のために”家”ができること
パナソニックのV2H蓄電システムで創る
エコなのに快適な未来の住宅環境
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」



 2024年、スマートウォッチはどう変わる?--AI機能強化、デザインも変化か
2024年、スマートウォッチはどう変わる?--AI機能強化、デザインも変化か  注目集めた指輪型にEV、「主役」はスマホからAIへ--MWC Barcelona 2024振り返り、日本企業は存在感高められるか
注目集めた指輪型にEV、「主役」はスマホからAIへ--MWC Barcelona 2024振り返り、日本企業は存在感高められるか  写真で見るモトローラの「手首に着けるスマホ」コンセプトモデル
写真で見るモトローラの「手首に着けるスマホ」コンセプトモデル